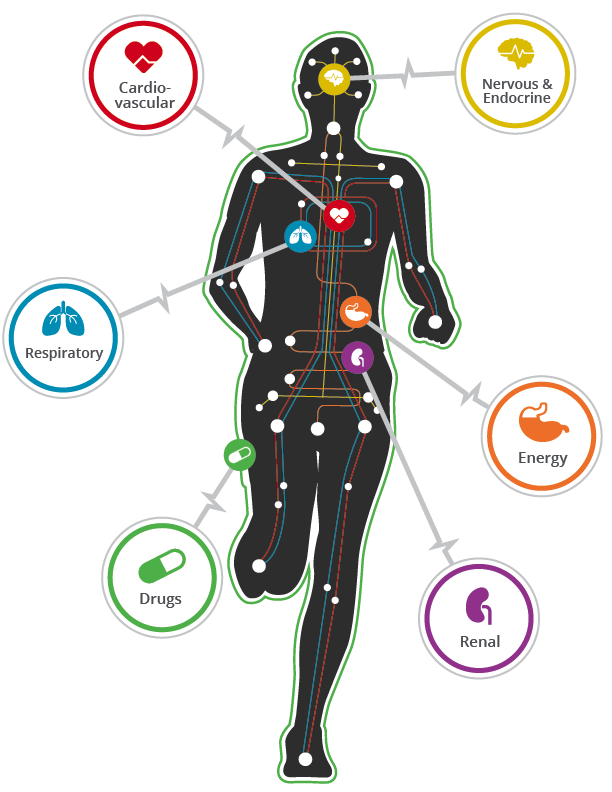
What is Pulse?
The Pulse Physiology Engine is a C++ based, open source, multi-platform (Windows, Mac, and Linux), comprehensive human physiology simulator that drives medical education, research, and training technologies. The engine enables accurate and consistent physiology simulation across the medical community. The engine can be used as a standalone application or integrated with simulators, sensor interfaces, and models of all fidelities. We are advancing the engine and exploring new avenues of research, such as pediatrics, patient-specific modeling, and virtual surgery planning/rehearsal.

Downloads
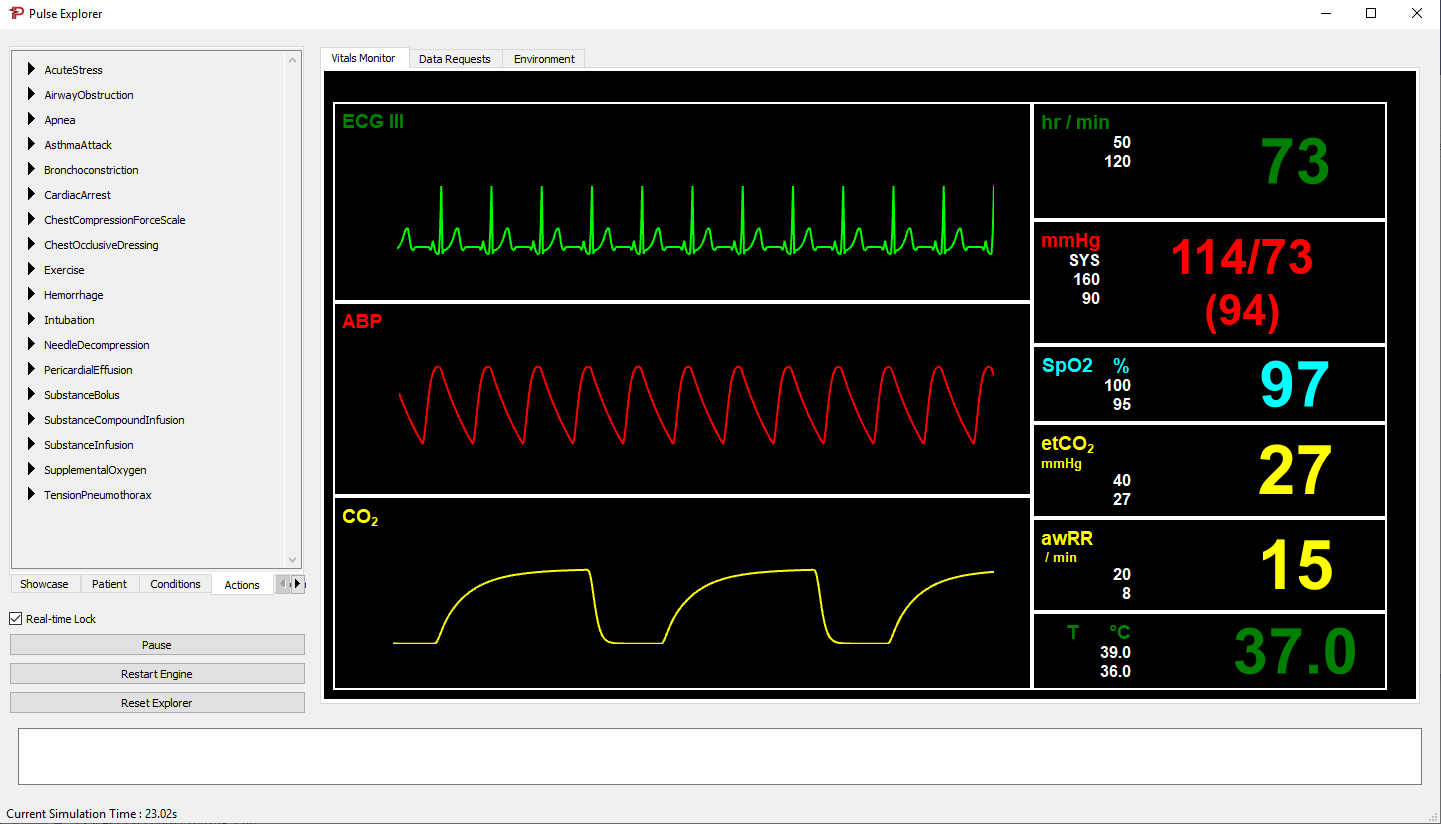
Pulse Physiology Explorer
The Pulse Physiology Engine is a powerful tool in computing the physiological responses to acute injury and treatment. As part of the Kitware physiology repository, we have developed a visualization tool built on Qt to provide a way to dynamically interact with the Pulse physiology engine. Prebuilt binaries are available.

Pulse Engine
The Pulse Engine repository contains all the code needed to build the engine.
Pulse is written in C++ and also provides an interface for other languages, including Java, C, C#, and Python.
Follow the Readme instructions on the repository to build your version of Pulse.
Leverage the provided resources for any issues building Pulse.
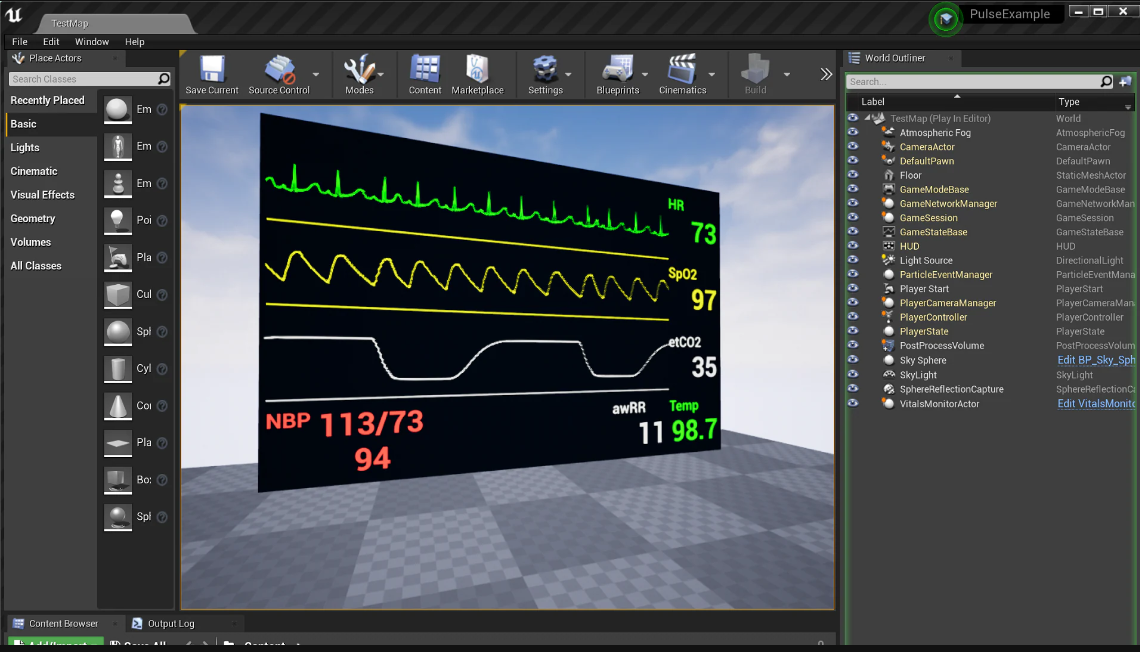
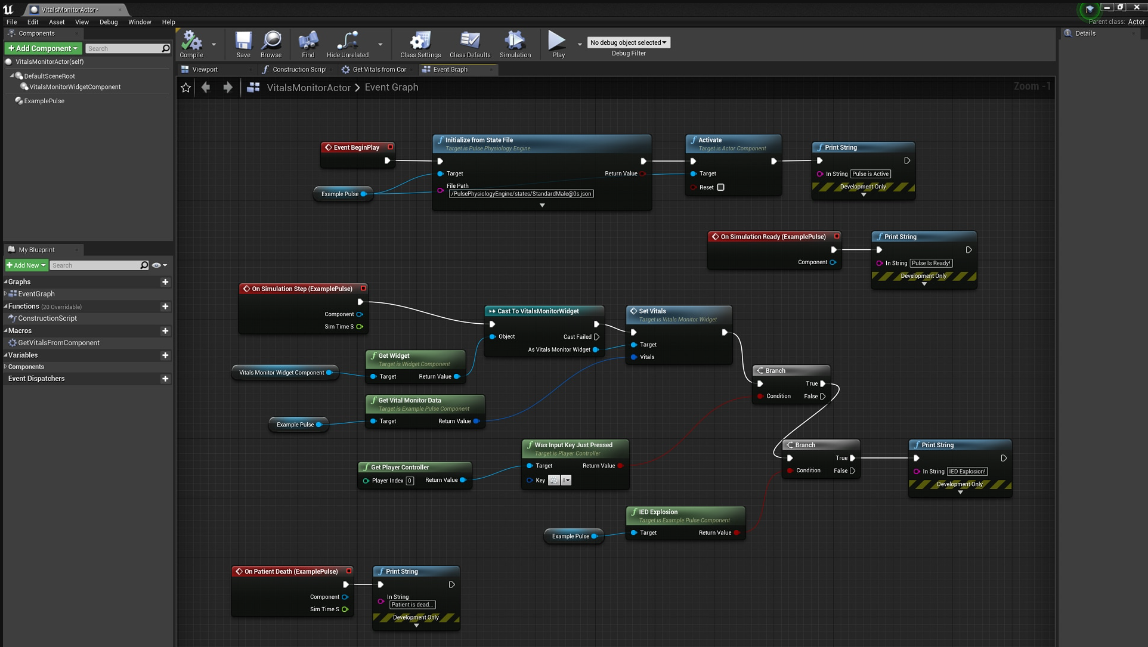
Pulse Unreal Plugin
The Pulse plugin encapsulates and exposes the Pulse Engine API via an Actor Component for Blueprint-based development.
Our plugin demonstrates how to use the Pulse component within a Blueprint to integrate with the game loop,
define and populate structures with data from Pulse, and define methods that encapsulate the creation of various Pulse actions.
Our repository also contains an example game with a vitals monitor you can use in your own applications.
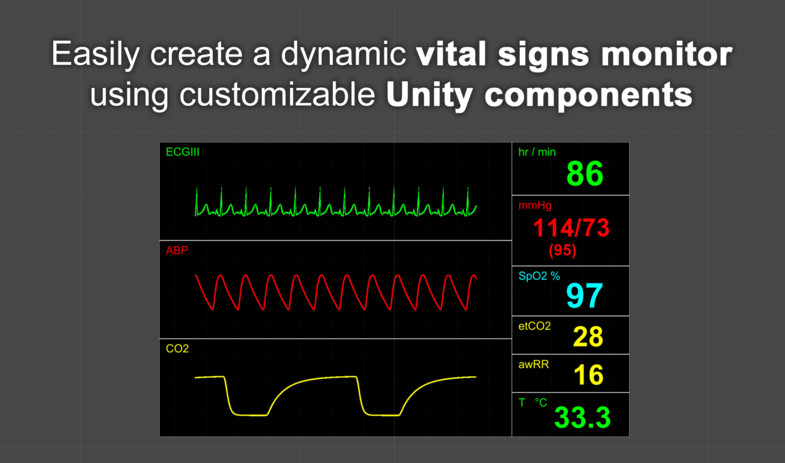

Pulse Unity Asset
The Pulse Unity Asset is available for free on the Unity Asset Store.
This Asset provides the Pulse C# API built for the Windows (32 & 64 bit), MacOS (Intel & Silicon), Linux, Android (Arm & Arm64), iOS, xrOS, and WebGL platforms.
Unity developers can easily import this assets to integrate the Pulse Physiology Engine into their Unity applications.
An optional vitals monitor is also provided.